
As someone passionate about both technology and Islamic studies, I recently came across a structured dataset of the Quran and decided to explore it through the lens of data analysis. What I discovered was a beautifully organized structure of the Holy Book—revealing patterns and insights that bridge spiritual depth and data clarity.
First, I load the Quran dataset from a CSV file, displays basic information about the dataset, and shows the first few rows for an initial inspection.
import pandas as pd
# Load the dataset
file_path = "The Quran Dataset.csv"
df = pd.read_csv(file_path)
# Display basic information and first few rows
df_info = df.info()
df_head = df.head()
df_info, df_head
The result is this :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6236 entries, 0 to 6235
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 surah_no 6236 non-null int64
1 surah_name_en 6236 non-null object
2 surah_name_ar 6236 non-null object
3 surah_name_roman 6236 non-null object
4 ayah_no_surah 6236 non-null int64
5 ayah_no_quran 6236 non-null int64
6 ayah_ar 6236 non-null object
7 ayah_en 6236 non-null object
8 ruko_no 6236 non-null int64
9 juz_no 6236 non-null int64
10 manzil_no 6236 non-null int64
11 hizb_quarter 6236 non-null int64
12 total_ayah_surah 6236 non-null int64
13 total_ayah_quran 6236 non-null int64
14 place_of_revelation 6236 non-null object
15 sajah_ayah 6236 non-null bool
16 sajdah_no 15 non-null float64
17 no_of_word_ayah 6236 non-null int64
18 list_of_words 6236 non-null object
dtypes: bool(1), float64(1), int64(10), object(7)
memory usage: 883.2+ KB
(None,
surah_no surah_name_en surah_name_ar surah_name_roman ayah_no_surah \
0 1 The Opener الفاتحة Al-Fatihah 1
1 1 The Opener الفاتحة Al-Fatihah 2
2 1 The Opener الفاتحة Al-Fatihah 3
3 1 The Opener الفاتحة Al-Fatihah 4
4 1 The Opener الفاتحة Al-Fatihah 5
ayah_no_quran ayah_ar \
0 1 بِسْمِ ٱللَّهِ ٱلرَّحْمَٰنِ ٱلرَّحِيمِ
1 2 ٱلْحَمْدُ لِلَّهِ رَبِّ ٱلْعَٰلَمِينَ
2 3 ٱلرَّحْمَٰنِ ٱلرَّحِيمِ
3 4 مَٰلِكِ يَوْمِ ٱلدِّينِ
4 5 إِيَّاكَ نَعْبُدُ وَإِيَّاكَ نَسْتَعِينُ
ayah_en ruko_no juz_no \
0 In the Name of Allah—the Most Compassionate, M... 1 1
1 All praise is for Allah—Lord of all worlds, 1 1
2 the Most Compassionate, Most Merciful, 1 1
3 Master of the Day of Judgment. 1 1
4 You ˹alone˺ we worship and You ˹alone˺ we ask ... 1 1
manzil_no hizb_quarter total_ayah_surah total_ayah_quran \
0 1 1 7 6236
1 1 1 7 6236
2 1 1 7 6236
3 1 1 7 6236
4 1 1 7 6236
place_of_revelation sajah_ayah sajdah_no no_of_word_ayah \
0 Meccan False NaN 4
1 Meccan False NaN 4
2 Meccan False NaN 2
3 Meccan False NaN 3
4 Meccan False NaN 4
list_of_words
0 [بِسْمِ,ٱللَّهِ,ٱلرَّحْمَٰنِ,ٱلرَّحِيمِ]
1 [ٱلْحَمْدُ,لِلَّهِ,رَبِّ,ٱلْعَٰلَمِينَ]
2 [ٱلرَّحْمَٰنِ,ٱلرَّحِيمِ]
3 [مَٰلِكِ,يَوْمِ,ٱلدِّينِ]
4 [إِيَّاكَ,نَعْبُدُ,وَإِيَّاكَ,نَسْتَعِينُ] )What Is the Quran Dataset?
The dataset contains 6,236 rows, each representing an individual ayah (verse) of the Quran. It’s organized into 19 columns, covering not only the text of each verse but also contextual and structural metadata.
Highlights of the Dataset:
- Surah Information: Includes the number and names of each surah in English, Arabic, and Romanized form.
- Ayah Content: Arabic text (ayah_ar), English translation (ayah_en), and a tokenized list of words (list_of_words).
- Structural Metadata: Information such as juz_no, ruko_no, manzil_no, and hizb_quarter.
- Contextual Metadata: Includes the place of revelation (Meccan or Medinan) and whether the verse includes a prostration instruction (sajah_ayah).
Initial Observations
After loading the dataset and performing a quick exploration, a few key points stood out:
- Data Integrity: The dataset is clean and complete in most fields. The only column with significant missing values is sajdah_no, which is relevant to only 15 verses that include prostration.
- Well-Structured Format: Each verse is traceable to its corresponding surah, juz, and other organizational divisions of the Quran, allowing for granular analysis.
- Ready for Text Analysis: With tokenized words available, this dataset is well-suited for natural language processing tasks such as word frequency analysis, semantic search, and clustering.
Example: The First Verse
Here is a quick look at the structure of the very first verse:
|
Column |
Value |
|
Surah |
1 – Al-Fatihah (الفاتحة) |
|
Ayah |
بِسْمِ ٱللَّهِ ٱلرَّحْمَٰنِ ٱلرَّحِيمِ |
|
Translation |
In the Name of Allah—the Most Compassionate, Most Merciful |
|
Juz |
1 |
|
Place of Revelation |
Meccan |
|
Number of Words |
4 |
|
Tokenized Words | [‘بِسْمِ’, ‘ٱللَّهِ’, ‘ٱلرَّحْمَٰنِ’, ‘ٱلرَّحِيمِ’] |
Meccan vs Medinan Revelations
The column place_of_revelation allows for a fascinating comparison between Meccan and Medinan verses. Traditionally, Meccan surahs focus on foundational beliefs and the afterlife, while Medinan surahs address social and legal aspects. This dataset provides a framework for investigating those differences quantitatively.
Next Steps
This exploration is just the beginning. With this dataset, I plan to:
- Visualize the distribution of ayahs across surahs and juz.
- Analyze linguistic patterns and frequently used roots.
- Explore thematic progression across the timeline of revelation.
- Build interactive tools for Quranic study and learning.
Visualize the distribution of ayahs across surahs and juz.
I visualized the distribution of ayahs across Surahs and Juz in the Quran dataset by creating bar charts to show the number of verses in each Surah and Juz.
# Load the dataset again
file_path = "The Quran Dataset.csv"
df = pd.read_csv(file_path)
# Visualize the distribution of ayahs across Surahs
plt.figure(figsize=(10, 6))
surah_ayah_counts = df.groupby('surah_name_en')['ayah_no_surah'].count()
surah_ayah_counts.plot(kind='bar', color='skyblue')
plt.title('Distribution of Ayahs Across Surahs')
plt.xlabel('Surah Name')
plt.ylabel('Number of Ayahs')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# Visualize the distribution of ayahs across Juz
plt.figure(figsize=(10, 6))
juz_ayah_counts = df.groupby('juz_no')['ayah_no_quran'].count()
juz_ayah_counts.plot(kind='bar', color='lightgreen')
plt.title('Distribution of Ayahs Across Juz')
plt.xlabel('Juz Number')
plt.ylabel('Number of Ayahs')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()Distribution of Ayahs Across Surahs
This chart shows how the number of ayahs varies across the surahs of the Quran. Some surahs contain more verses than others.
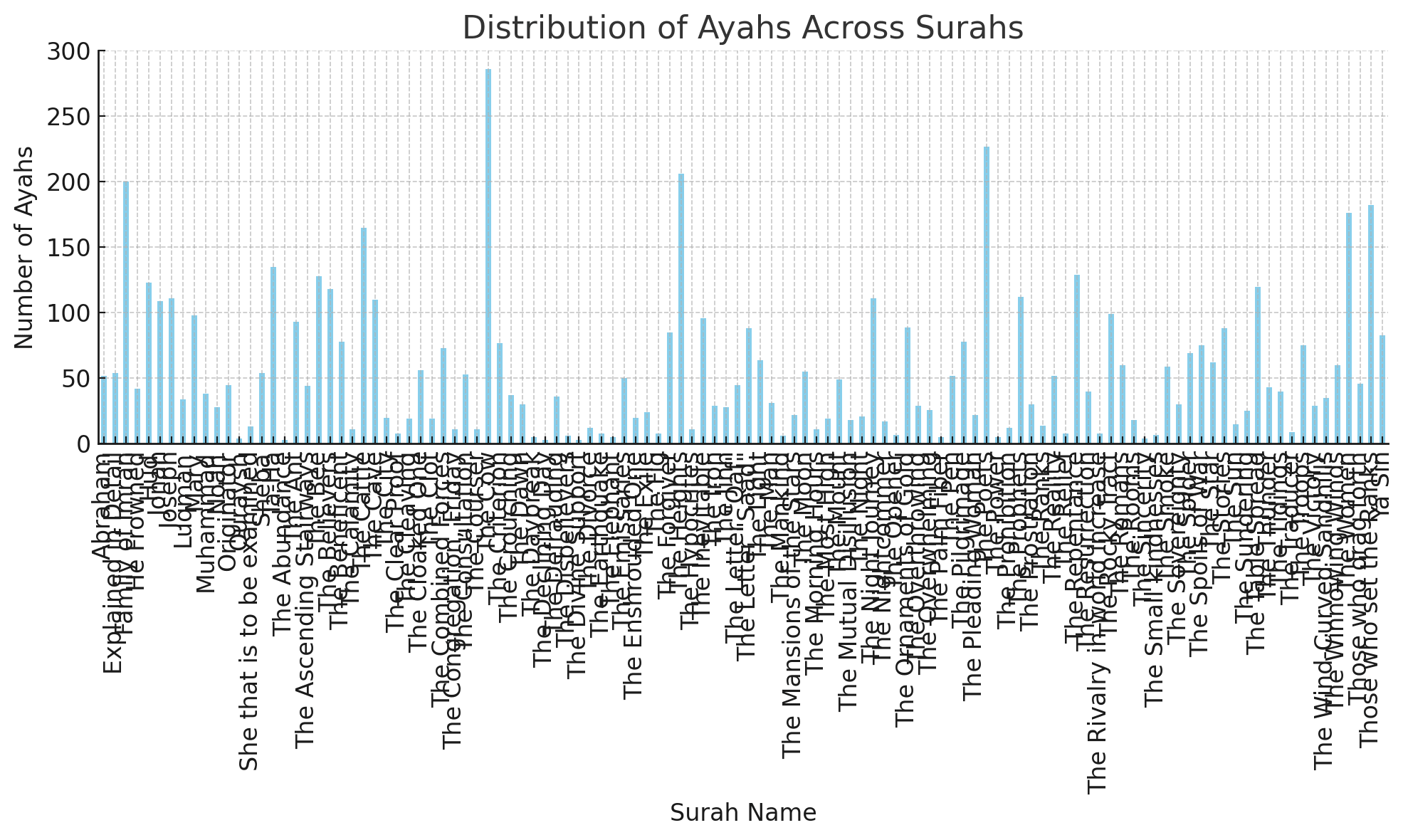
Distribution of Ayahs Across Juz
This bar chart illustrates the distribution of ayahs across the 30 Juz (sections) of the Quran.
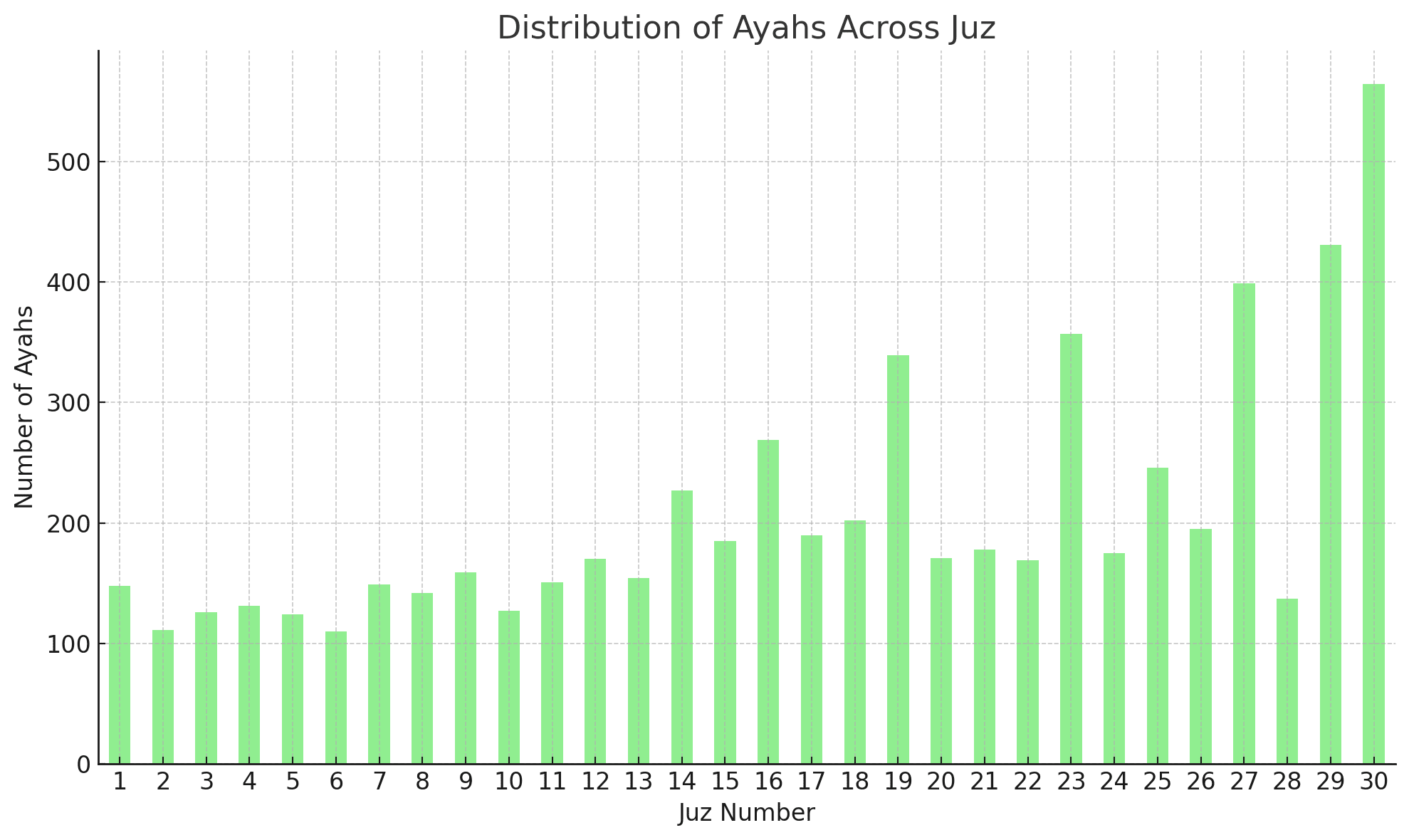
Meccan vs Medinan Revelations
I visualized the distribution of Meccan and Medinan revelations in the Quran dataset using a pie chart, displaying the percentage of verses revealed in Mecca and Medina.
# Plot Meccan vs Medinan revelations using a pie chart
plt.figure(figsize=(7, 7))
revelation_counts = df['place_of_revelation'].value_counts()
revelation_counts.plot(kind='pie', autopct='%1.1f%%', colors=['lightblue', 'lightcoral'], startangle=90, legend=False)
plt.title('Meccan vs Medinan Revelations')
plt.ylabel('')
plt.tight_layout()
plt.show()And here is the plot :
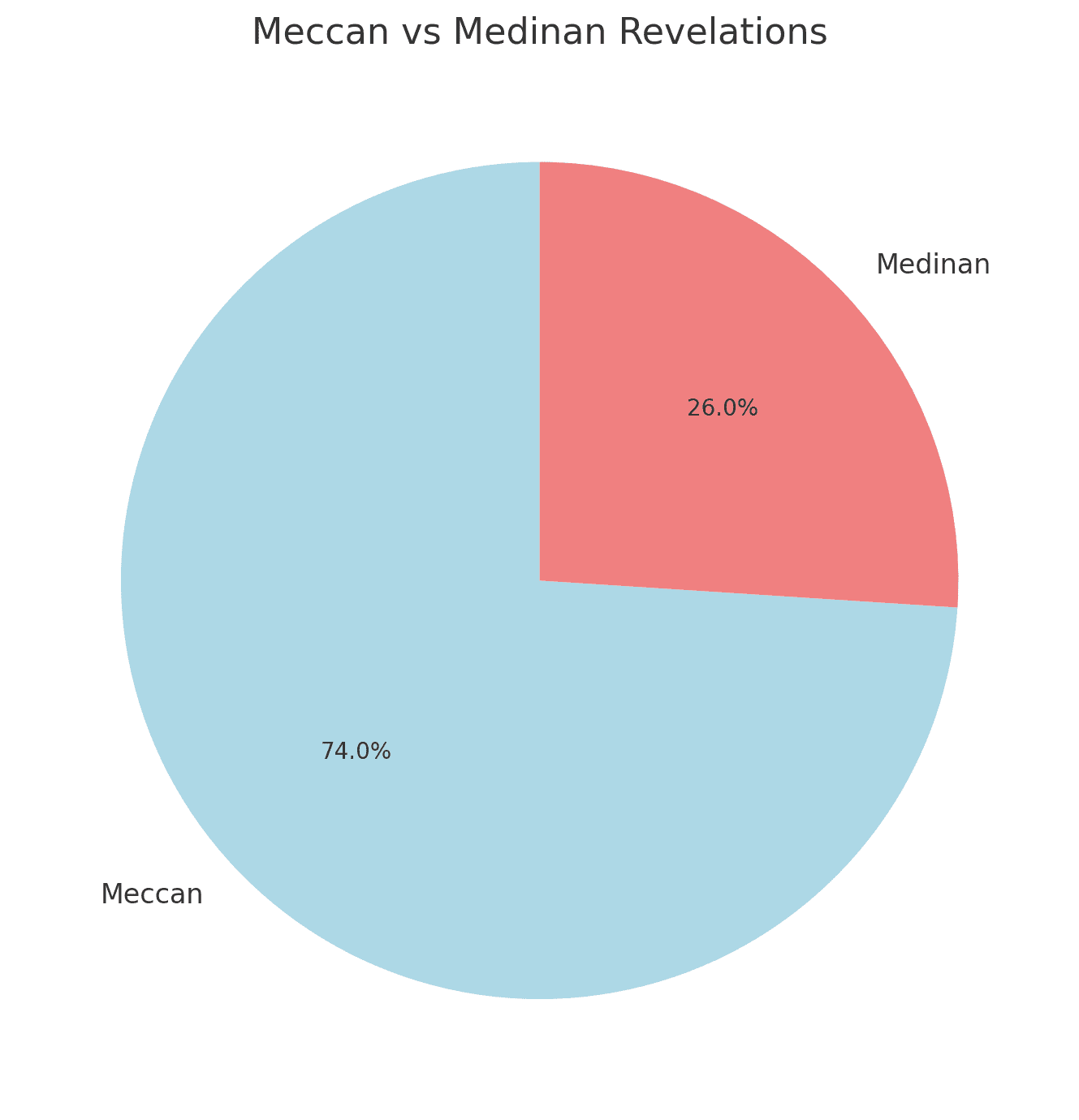
The Quran dataset serves as a powerful bridge between data science and spiritual study. Whether you’re a student of religion, a technologist, or both, this type of analysis offers a unique perspective on one of the most influential texts in history.
Dataset url : https://www.kaggle.com/datasets/imrankhan197/the-quran-dataset
